
全网都在扒的DeepSeek团队,是清北应届生撑起一片天
全网都在扒的DeepSeek团队,是清北应届生撑起一片天DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
来自主题: AI资讯
9987 点击 2025-01-04 15:15
 搜索
搜索
DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
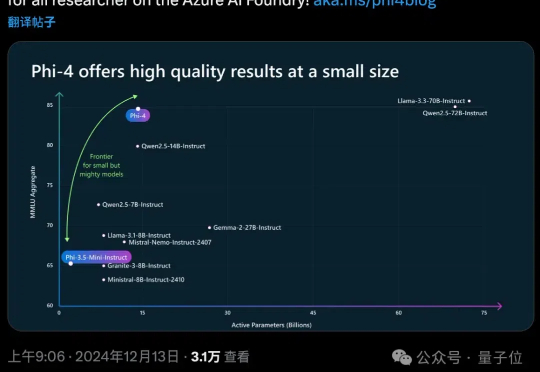
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。

OpenAI“双12”刚进行到第二天,就把大模型圈搅得好不热闹! 一边是Meta没预告就发布了Llama 3.3,70B版本就能实现以前405B的性能。

Llamacoder是Claude Artifacts的开源实现。 最大的亮点就是,左侧AI写代码,右侧实时渲染。 之前给大家推荐过一个基于Claude做的,Llamacoder是用了Meta 的 Llama 3.1 405B 作为底层语言模型。
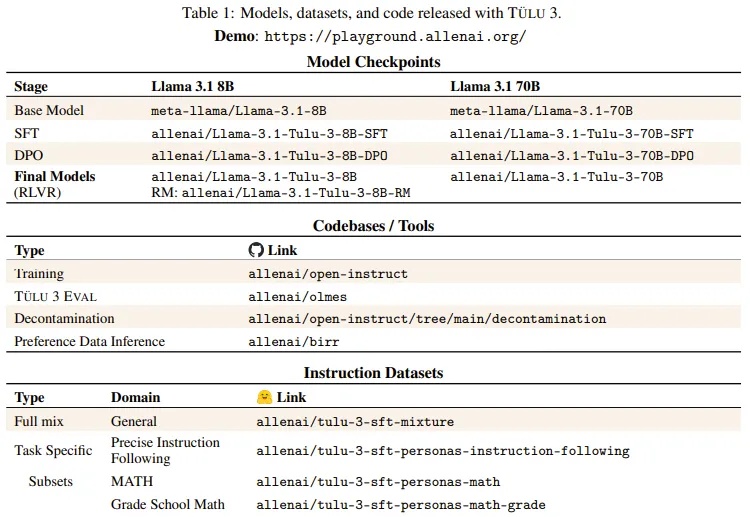
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。
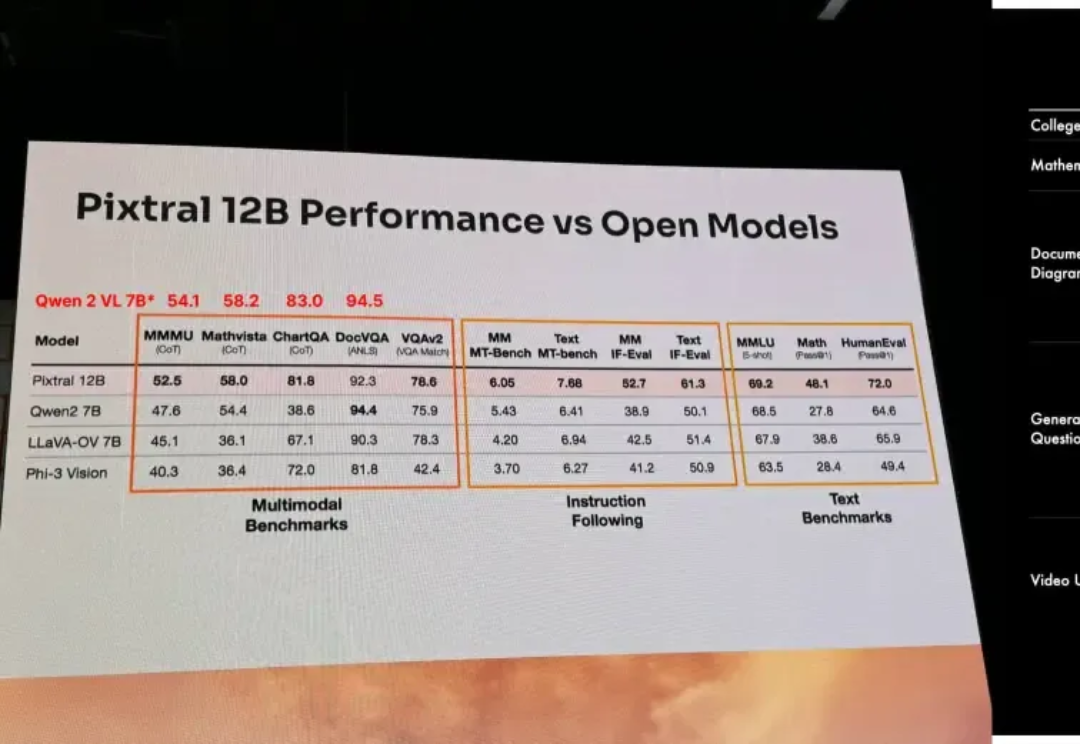
以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。
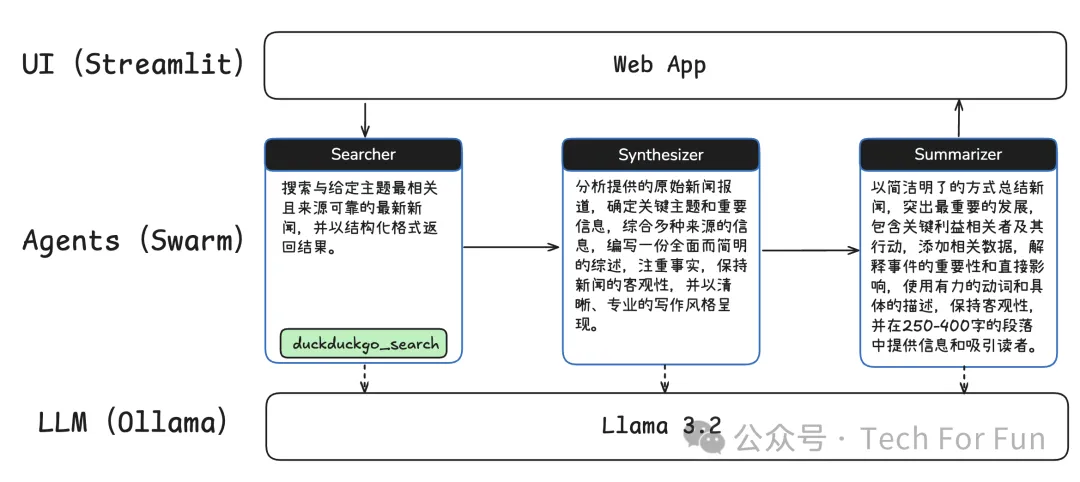
本文将带你构建一个多智能体新闻助理,利用 OpenAI 的 Swarm 框架和 Llama 3.2 来自动化新闻处理工作流。在本地运行环境下,我们将实现一个多智能体系统,让不同的智能体各司其职,分步完成新闻搜索、信息综合与摘要生成等任务,而无需付费使用外部服务。

北京时间 10 月 30 日,GitHub Universe 2024 如约而至,而今年正值大会十周年纪念日。本文将从 GitHub 发布的 AI 新进展入手,围绕开源模型、用户数量、盈利模式、发展历程等几个方面,全面梳理 GitHub 与 Hugging Face 两大开源平台的异同。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。